
本测评结果仅用于学术研究
天工大模型简介
天工大模型是昆仑万维自研的千亿级大语言模型,于今年4月17日首发内测。近日,CLUE社区发现「天工」大模型v3.5在多个评测数据集上表现抢眼,尤其在推理评测集GSM8K上超过了GPT-3.5和LLaMA2-70B,引起了CLUE社区众多开发者广泛热议。

那么,天工大模型在我们的测评集上是否能有不错的表现?与国内外大厂以及科研机构开发的代表性模型相比相对表现如何;在一些比较关注的能力上,如生成与创作、逻辑推理、代码生成,表现怎么样?我们基于SuperCLUE综合性测评基准,包括多轮开放式问题测评SuperCLUE-OPEN和三大能力客观题测评SuperCLUE-OPT,用3337道题对天工大模型进行了全方位测评。
测评环境
参考标准:SuperCLUE综合性测评基准
评测模型:天工大模型v3.5.20230915.a
评测集:共3337道中文题,其中623道简答题和2714道选择题。包括基础能力、学术专业、中文特性三大评测维度的74个评测任务。
模型GenerationConfig配置:
generate_length: 2048
repetition_penalty: 1
temperature: 0.8
top_k: 3
top_p: 1
测评方法:本次测评为自动化评测,具体评测方案可查阅SuperCLUE综合性测评标准。本次测评经过人工抽样校验。
先说结论
结论1:在SuperCLUE基准上,天工大模型在综合能力上处于中文闭源模型第一梯队,是一个很有竞争力的大模型。
结论2:天工大模型进一步缩小中文闭源模型与GPT3.5的差距。
结论3:天工大模型是一个能力均衡的大模型,各个任务上表现无明显短板,并且在语言理解、计算和逻辑推理能力上较为突出。
以下是从定量和定性两个角度对模型进行的测评分析。
测评分析
1、 定量分析
我们参考8月SuperCLUE榜单的国内外代表性模型,用以对比天工大模型的表现。
SuperCLUE大模型综合评测
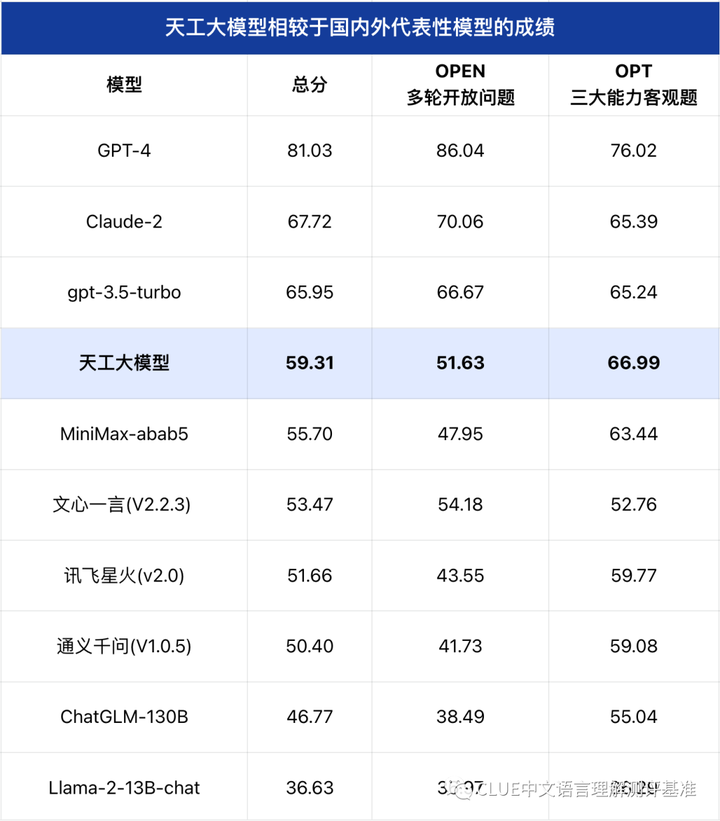
注:总分=50%*OPEN+50%OPT
通过测评结果我们可以看到,在8月superclue评测集上天工大模型在国内闭源模型中表现不俗。天工大模型在十大基础能力上的表现
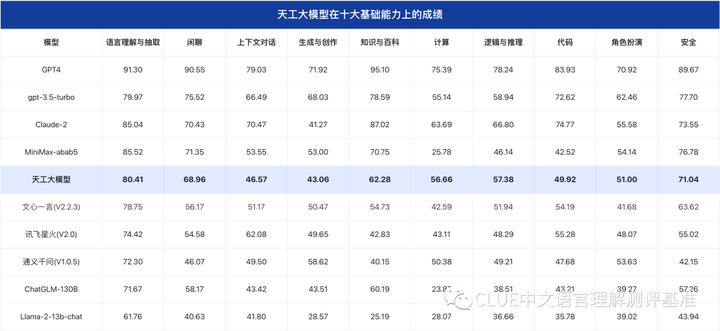
注:十大能力分数为OPEN分数和OPT分数的加权平均
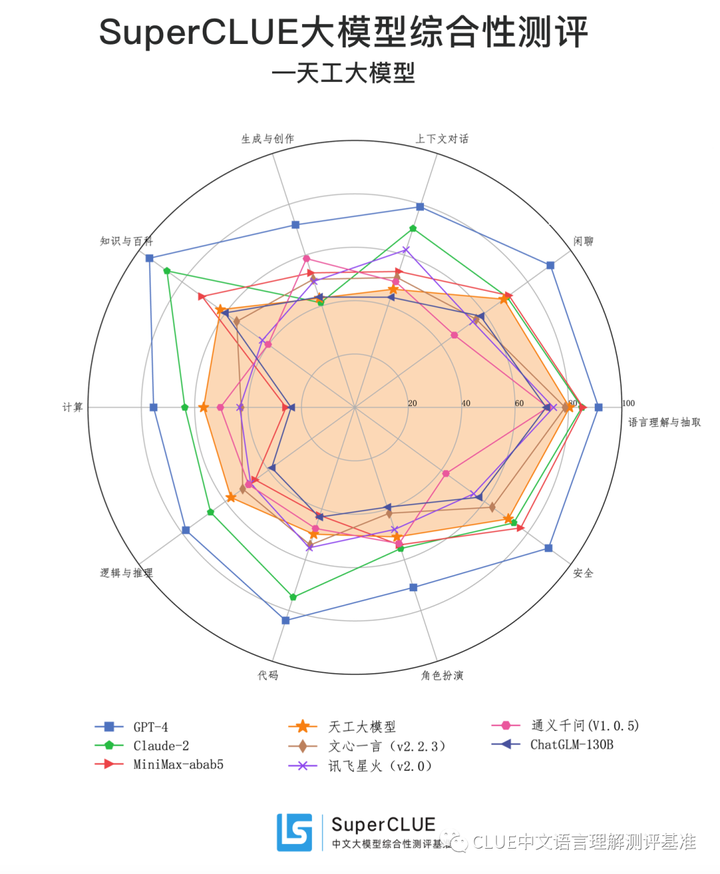
通过评测结果我们可以看到,天工大模型在十大任务上非常均衡,并且通过与中文闭源模型平均成绩对比发现,天工大模型在在各项任务上均在平均线之上,这在当前的中文模型中较为罕见。
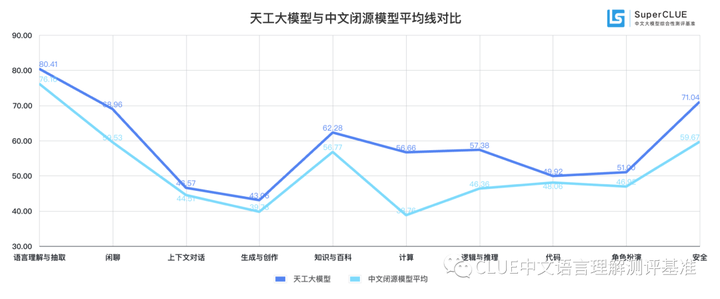
小结:
从评测数据我们发现,天工大模型在综合能力上表现非常抢眼,在总分上处于国内大模型第一梯队,并且能力非常均衡无明显短板,在语言理解、生成创作、计算、逻辑推理方面都表现不错。需注意的是,本次评测的天工大模型为9月15日更新版本,对比的其他国内模型为8月评测结果,后续SuperCLUE会进一步对比。
2、定性分析通过一些典型示例,对比定性分析天工大模型的特点。
逻辑与推理
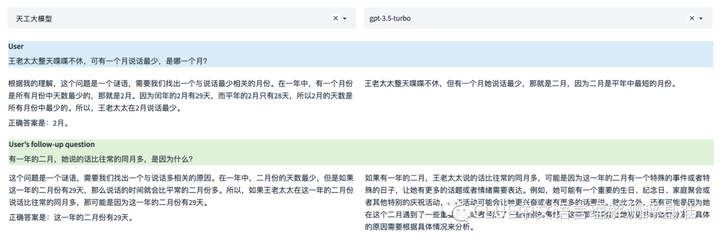
在本示例的第一轮问题中,两个模型都回答正确。其中gpt-3.5-turbo的答案比较简洁,天工大模型推理步骤相对完整。而在第二个问题中,gpt-3.5-turbo未能准确回答出正确答案,虽然也包含了一些可能影响王老太太说话数量的因素,但它没有明确指出这是因为闰年二月有29天。天工大模型则直接给出了问题的答案。本示例中天工表现更好一些。
计算

在本示例中,两个模型都给出了正确的一阶和二阶导函数,并且详细解释了计算过程,所以从正确性和计算过程评估,两个模型表现相当。
生成与创作

两个模型都很好地回答了用户问题。天工大模型的回答更注重道出生活的哲理,强调的是希望的力量和意义。gpt-3.5-turbo的回答更像是一个实际的生存故事。从实用性、相关性、准确性、深度和创造性来看,两个模型的回答都很好。
语言理解与抽取

在本示例中,天工大模型识别出了文本中的每个环节都包含积极的情感元素。它的回答深入、准确,并且直接回应了用户的问题。gpt-3.5-turbo的回答采取了逐步分析的方式,识别出了文本开头的消极情绪,然后逐步指出了积极情感的出现和占据主导地位。这种回答方式也是准确和详细的,但提供了更多的步骤和细节。所以综合来看,两个模型的答案都非常不错。
小结:
从定性分析的示例我们可以发现,天工大模型几个关键基础能力上很接近gpt-3.5-turbo,尤其在逻辑与推理、计算方面有很不错的表现。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。














