
本次收录的论文成果聚焦大模型训练与指令微调的数据工程、可解释表征与稳健泛化等前沿方向,为思必驰大模型人机对话产品的核心能力提供技术支撑。相关研究成果在实际应用中,支撑了多智能体协同与复杂任务拆解执行、提升了Agent的自治规划与容错能力,在端到端语音理解与生成中实现了更高的鲁棒性与跨模态一致性,同时为生态Agent的分发管控与个性化对话记忆提供了可解释的模型基础。这些进展让产品在车载语音、家庭助手、客服中台等场景下,能够以更稳定、更智能、更自然的方式完成任务与交互,推动人机协同体验的全面升级。下面介绍本次收录的代表性成果:
指令微调的数据选取与可解释表征学习
Task-Specific Data Selection for Instruction Tuning via Monosemantic Neuronal Activations
以模型内部神经元激活而非仅文本语义来表征样本,并通过稀疏自编码器将多义激活解耦为可解释的“单义”特征,在稀疏空间完成任务对齐与相似度度量,实现更稳健的数据精选,为企业级指令微调与垂直应用提供“少而精”的数据基座。
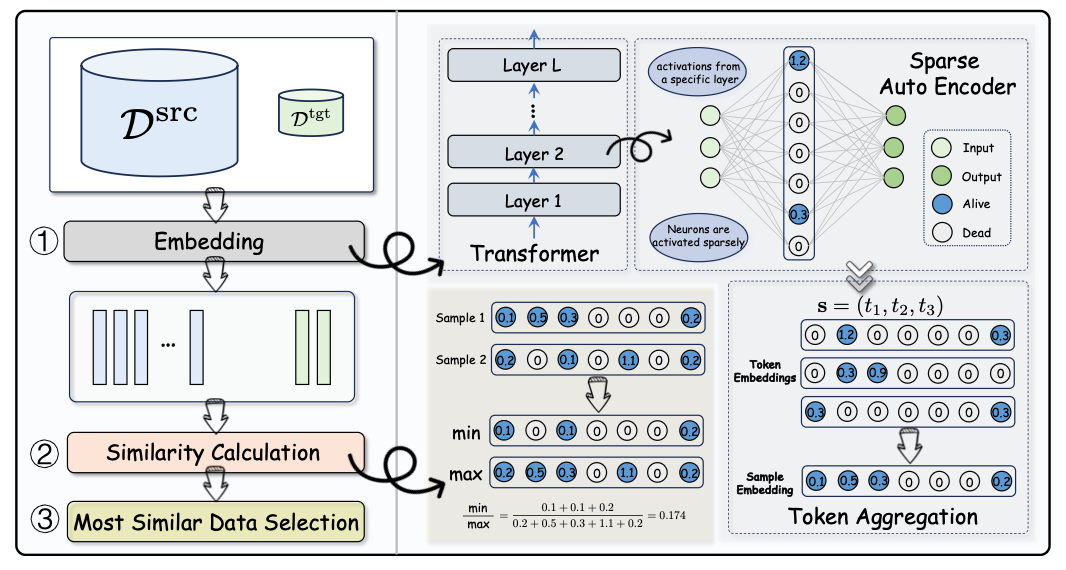
论文简介:指令微调显著提升了大语言模型对多样化人类指令的遵循能力,但在特定目标任务上取得更优表现的关键瓶颈在于如何以尽可能小的代价挑选最相关的数据。现有方法要么依赖易受噪声与实现细节影响的影响力估计,要么采用稳定但高度依赖样本表征质量的分布对齐。而无论是BM25等浅层特征,还是BGE、LLM2Vec等神经嵌入,都往往难以反映模型实际的内部计算。为此,本文提出以模型为中心的数据选择范式MONA:以基座模型特定层的神经元激活直接表征样本,使表示与模型决策过程同构。再利用稀疏自编码器将多义激活解耦为稀疏、可解释的单义特征,并在该空间构建更契合稀疏性的相似性度量以对齐目标任务原型,从而稳健打分并筛选候选样本。覆盖多数据源、多任务、多模型与多选取比例的系统实验表明,MONA在稳定性与任务特定性能上持续优于现有基线。在若干设置下,经MONA精选的少量数据即可达到或超过全量微调的效果,同时显著降低训练成本并提升可解释性与迁移性。
长期以来,思必驰深度参与国内外学术前沿研究,在ICASSP、INTERSPEECH、ACL、EMNLP、AAAI、ICML、NeurIPS等顶级学术会议上屡获佳绩,持续产出高质量科研成果。思必驰-上海交大联合实验室凭借一系列高水平论文,彰显了在人工智能语音语言关键技术领域的深度探索和重大突破,为行业的发展注入了强大动力。思必驰秉持科研与产业应用紧密结合的理念,未来也将持续探索科技成果的应用转化。
作为专业的对话式人工智能平台型企业,思必驰具有源头技术创新和应用创新的能力,自2022年7月获国家科技部批准建设“语言计算国家新一代人工智能开放创新平台”以来,接连于2023-2024年获批组建苏州市、江苏省、长三角三级创新联合体,并于2025年携手上海交通大学、苏州大学,牵头组建“江苏省语言计算及应用重点实验室”,成为国家人工智能战略科技力量的重要组成部分。
思必驰承担了包括国家重点研发计划、国家发改委“互联网+”重大工程和人工智能创新发展工程、国家工信部人工智能与实体经济深度融合项目、长三角科技创新共同体联合攻关计划项目等十余项国家级、省部级项目,展现出卓越的科研实力与项目落地能力。
思必驰深耕语音语言领域,凭借自主研发的核心技术多次在国际研究机构评测中夺得冠军;曾三度斩获国内人工智能最高奖“吴文俊奖”,荣获中国专利优秀奖,以及信通院车载智能语音交互系统最高级别认证等重要荣誉。技术创新能力备受全球瞩目,被高盛全球人工智能报告列为关键参与者,也被Gartner评为东亚五大明星AI公司之一。
截至2024年年底,思必驰拥有近100项全球独创技术,已授权知识产权1597件,其中已授权发明专利633项,参与了71项国家/行业/团体标准,获得23项国家级的产品认证。近期,大模型人机对话技术创新与产业赋能发展提速,思必驰坚持自主的大模型技术路线,即“构建可靠性优先的1+N分布式智能体系统:1 个中枢大模型+ N 个垂域模型及全链路交互组件组成全功能系统”,以任务型交互为核心,结合智能硬件感知优势,构建垂域大模型和中枢大模型系统,服务企业客户。














